This post is part of a series reimplementing one of my past projects using technology available these days; for a general overview, please see the prologue.
Continuing on from last time, the design of the system as a whole is, intentionally, pretty boring. I think boringness is underrated by developers as a whole; I actually want my projects — especially my work projects! — to be as boring as possible because it buys you predictability. Using the latest new tech toy is fine for experiments and personal stuff — indeed, it’s the best way to discover useful new pieces — but when other people are relying on your systems, you should reach for what you know works. Luckily these days the “stable edge” follows the bleeding edge pretty well (just a bit behind it).
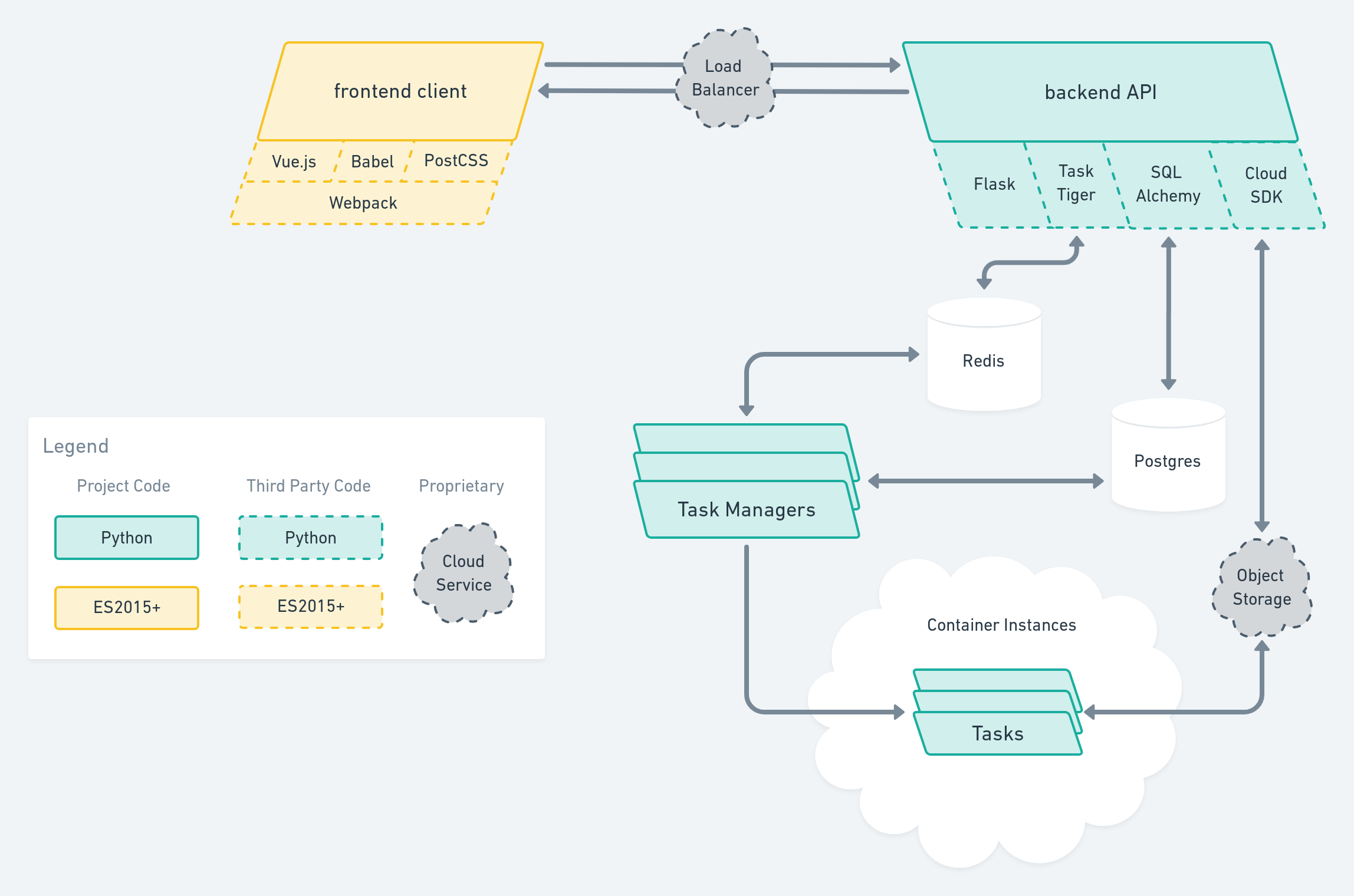
This design is a standard frontend client/backend API/data store system with a couple of twists. First is that because we want to run jobs asynchronously, there is a task queue based on Redis linking the backend API to the task workers. I am actually ambivalent about using Redis to maintain state for a task queue, but as long as we are not running Slack-level workloads I think in the end it’s fine.
The other twist is that instead of running the tasks inside the task queue workers themselves (which is perfectly fine for normal-sized asynchronous tasks) we are going to farm out the execution of the tasks to a container instance service like Azure Container Instances.1 This is because our tasks (video transcoding and compositing, remember) are not lightweight; this way we can give as much or as little resources as we want specifically to the most compute-centric part of the system, and in turn we can control exactly how much each task execution will cost us.
This is something that I could only dream about the first time I implemented this project: lightweight orchestration with heavy compute resources available on demand. In fact, for light loads (such as this demo) this whole system will run quite well on a single machine; if we asked it to do the video tasks as well on that same machine, we might get away with doing them one at a time, but if ever we asked it to do several in parallel we’d definitely have been sunk.
Now for the details of our implementation… the frontend will be a Vue.js-based app which acquires images from the user — perhaps initially as just a file upload and simple cropping interface; later iterations could use the camera to take a photo of the user if they prefer. We’ll write it in modern JS/ES2015+ and use Babel to transpile it down so that it can run on ES5-supporting browsers. (This should cover 97.43% of visitors, as of the writing of this post.)
The frontend client code will talk to the backend API. The backend will also serve to bootstrap the client code by initially serving the webapp, of course, but its main function is to offer a set of REST APIs that can be used by the client code to authenticate the user, submit new jobs, and track the progress of running jobs. It will be a Flask-based app, using SQLAlchemy to talk to a Postgres DB (see? boring!) and use a cloud object storage system such as Azure Storage1 to store submitted resources and make them available to the tasks. TaskTiger will be used to manage the task queue, with independent workers picking up task requests from the queue and managing the execution of the task on the container instance service. For simplicity, each task queue worker will only manage one task at a time, so scaling up the number of parallel tasks means running more workers.
The video tasks themselves will be implemented as simple cli-based scripts run in containers on the container instance service that take in the name of a video and a pointer to the requested image to composite, do the compositing, and upload the completed output videos to the cloud object storage system. Each task manager will be responsible for keeping track of its task starting, progressing, and ending (or crashing). As an additional complication (just to keep things interesting) the task managers should also be able to “pick up” orphaned running tasks in the event that their old task managers disappear (due to worker crashes and new deployments), as well as kill running tasks that are taking too long. The task managers will update the current execution status of each task in Postgres.
It’s time to start coding! Next time we will look at implementing the backend portions of the system.
- <voice style="bbc-host">Other brands of container instances and cloud storage are available.</voice> ↩